
Web scraping is the process of data extraction from different websites. It is done by using a piece of code known as “scraper”. It includes sending a ‘GET’ type query and then HTML parsing of the received content. After parsing, the scraper searches for the specified data and convert it into the specified document.
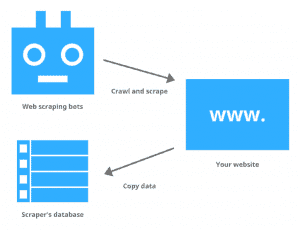
The data can be the following:
- Product items
- Images
- Videos
- Text
- Contact information, e.g. emails, phone numbers and etc.
Purposes of web scraping
- Content scraping – The content can be extracted from the website in order to replicate/obtain the unique benefit of the product or service which relies on that content. For example, a B2C website sells the same product as the other website. So, one website owner can scrape the reviews of the same product from the other website to build customer confidence.
- Price scraping – The scraping of pricing information can help the business owners to know about their competitors and devise pricing strategies.
- Contact scraping – The contact scraping can be used to find potential targets for any sale or marketing campaign. But, many social engineering attackers benefit from this technique to spam a lot of users.
How to stop it?
In reality, there is no way to stop web scraping. A skillful scraper can scrape a whole public-facing website page by page if given enough time. This vulnerability lies due to the fact that any piece of information which is visible insider a web browser must be downloaded before it can be rendered. In plain words, to let a visitor see the content, all website content must be transferred to its machine and any part of information a visitor is able to access can be scraped. However, we can limit the extent of web scraping.
- Rate the limit requests – It is easy to predict the human speed of interacting with a website. For example, a human can hardly browse 4-5 pages of a website in 5 minutes. On the contrary, a computer can access hundreds of web pages within seconds. So, by rating the limit requests, we can limit the number of requests from a particular IP in a given time frame. It will help us to avoid web scraping attempts.
- Modification of HTML markups at regular intervals – The web scraping software relies on the consistent formatting in order to effectively scrape the whole website and parse out and save the data. One strategy of interrupting the smooth scraping attempt is to frequently change the HTML markups so that consistent scraping can become more difficult.
- Use CAPTCHA pattern for high volume requests – Other than rate limit requests, another effective strategy is to use CAPTCHA pattern that will ask users to solve a challenge or a riddle which is difficult for a computer.